 Skip to content
Skip to content 
Introduction
Machine learning ML has become an essential part of modern technology, driving innovations in a wide range of fields such as healthcare, finance, entertainment, and even transportation. From self driving cars to personalized movie recommendations, the applications of ML are vast and growing. However, despite its widespread use, many people still find the concept of machine learning complex and difficult to grasp. This guide aims to provide an accessible and comprehensive introduction to machine learning, breaking down its essential concepts and offering practical insights for beginners.

What is Machine Learning?
Machine learning is a subset of artificial intelligence AI that focuses on developing algorithms that allow computers to learn from data without explicit programming. In traditional programming, a programmer writes instructions that tell the computer exactly what to do. In contrast, with machine learning, the system learns patterns from data and uses those patterns to make predictions or decisions on new data. This ability to learn from experience is what sets ML apart from conventional programming.
The goal of machine learning is to create models that can identify patterns in data and use those patterns to make predictions or take actions. These models can improve over time as they are exposed to more data, which is why machine learning is often described as a form of learning from experience.
Types of Machine Learning
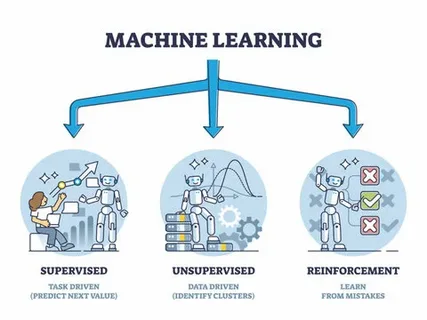
Machine learning can be broadly categorized into three main types:
Supervised Learning
In supervised learning, the algorithm is trained using a labeled dataset. This means that the input data comes with known outputs, or labels. The goal is for the model to learn the relationship between the input and output so that it can predict the output for new, unseen data.
Example: A spam email classifier that learns to distinguish between spam and non spam emails based on labeled training data emails labeled as spam or not spam.
Unsupervised Learning
In unsupervised learning, the model is given input data without labels. The goal is to find hidden patterns or structures within the data. Unsupervised learning is often used for clustering, anomaly detection, and dimensionality reduction tasks.
Example: A recommendation system that groups similar products based on customer browsing behavior without knowing in advance which products are popular.
Reinforcement Learning
In reinforcement learning, an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties, which helps it learn how to optimize its actions to maximize cumulative rewards. This type of learning is used in areas such as robotics and game playing AI.
Example: A robot learning to navigate a maze by receiving rewards for moving closer to the goal and penalties for moving in the wrong direction.
The Machine Learning Process
Machine learning follows a series of steps that allow it to process data and learn from it. The typical ML workflow consists of the following stages:
Data Collection
The first step in any machine learning project is to collect data. The quality and quantity of data are critical to the success of the ML model. Data can come from various sources, such as sensors, web scraping, or publicly available datasets.
Data Preprocessing
Raw data is often messy and incomplete. Preprocessing involves cleaning and transforming the data to make it suitable for analysis. This step may include handling missing values, normalizing data, and encoding categorical variables.
Feature Engineering
Feature engineering is the process of selecting and transforming the relevant features or variables from the data that will be used to train the model. The right set of features can significantly improve model performance.
Model Training
In this stage, the chosen algorithm is trained on the preprocessed data. During training, the model learns to make predictions by adjusting its internal parameters based on the data. The training process may involve optimization techniques such as gradient descent.
Model Evaluation
After training, the model is tested on new, unseen data to evaluate its performance. This step helps determine how well the model generalizes to real world data. Common evaluation metrics include accuracy, precision, recall, and F1 score.
Model Tuning
If the model performance is not satisfactory, hyperparameter tuning is done to adjust the model settings for better results. This may involve adjusting parameters like learning rate or the number of layers in a neural network.
Deployment
Once the model is trained and evaluated, it is deployed into a real-world environment where it can start making predictions or decisions. This can involve integrating the model into an application or system that can process live data.
Monitoring and Maintenance
After deployment, continuous monitoring is essential to ensure the model remains effective as new data comes in. The model may need retraining over time as data patterns change.

Machine Learning Algorithms
Several types of algorithms are commonly used in machine learning. Here are some of the most widely used ones:
Linear Regression
Linear regression is one of the simplest algorithms in machine learning. It is used to model the relationship between a dependent variable and one or more independent variables. It is typically used for prediction tasks.
Example: Predicting the price of a house based on features such as square footage, number of bedrooms, etc.
Logistic Regression
Despite its name, logistic regression is a classification algorithm used to predict binary outcomes 0 or 1, true or false. It is commonly used for problems like spam detection or disease classification.
Decision Trees
Decision trees are a non linear classification and regression algorithm. They work by splitting the data into subsets based on feature values, creating a tree like structure of decisions.
Example: A decision tree could be used to predict whether a customer will buy a product based on age, income, and browsing behavior.
Random Forests
Random forests are an ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting. Each tree in the forest is trained on a random subset of the data, and the final prediction is made by averaging or voting.
Support Vector Machines SVM
SVM is a powerful classification algorithm that works by finding the hyperplane that best separates the data into classes. It is particularly effective in high dimensional spaces.
K Nearest Neighbors KNN
KNN is a simple, instance based algorithm that classifies data points based on their proximity to other data points. It is often used in classification tasks with small datasets.
Neural Networks
Neural networks are a class of algorithms inspired by the human brain. They consist of layers of interconnected nodes neurons that process data. Deep learning, a subset of ML, uses deep neural networks to handle complex tasks such as image recognition and natural language processing.

Applications of Machine Learning
Machine learning has applications in almost every industry. Here are some of the most notable areas where ML is making an impact:
Healthcare
ML is transforming healthcare by enabling predictive diagnostics, personalized treatment, and drug discovery. For example, ML models can analyze medical images to detect diseases like cancer at an early stage.
Finance
In finance, ML algorithms are used for fraud detection, credit scoring, algorithmic trading, and customer risk profiling. These models help financial institutions make data driven decisions.
Retail and E Commerce
Retailers use ML for personalized recommendations, inventory management, and demand forecasting. Amazon, for example, uses machine learning to recommend products based on user behavior.
Autonomous Vehicles
Self driving cars rely heavily on machine learning to interpret sensor data, recognize objects, and make driving decisions. ML models help these vehicles navigate safely and efficiently.
Natural Language Processing NLP
NLP is a branch of ML that deals with processing and understanding human language. Applications include chatbots, sentiment analysis, language translation, and speech recognition.
Entertainment
Streaming platforms like Netflix and Spotify use ML algorithms to recommend content based on user preferences, improving the user experience and engagement.
Challenges in Machine Learning
While machine learning has shown great promise, there are several challenges that researchers and practitioners face:
Data Quality
Machine learning models are only as good as the data they are trained on. Poor quality or biased data can lead to inaccurate predictions.
Overfitting
Overfitting occurs when a model learns the training data too well, capturing noise and outliers instead of general patterns. This leads to poor performance on new data.
Computational Power
Training complex ML models, especially deep learning models, requires significant computational resources. This can be a barrier for smaller organizations or individuals with limited access to powerful hardware.
Ethics and Bias
ML models can inherit biases present in the training data, leading to unfair or discriminatory outcomes. Ensuring fairness and transparency in ML algorithms is a growing concern in the AI community.
Interpretability
Many ML models, especially deep learning models, operate as black boxes, making it difficult to understand how they arrive at a decision. This lack of transparency can be a problem in high stakes applications like healthcare or finance.
Future of Machine Learning
The future of machine learning is incredibly exciting. As technology continues to evolve, we can expect even more sophisticated and powerful models. Some of the key trends in ML include:
Automated Machine Learning Auto ML
Auto ML is the process of automating the end to end process of applying machine learning to real world problems. It makes machine learning accessible to people without a deep background in the field.
Explainable AI XAI
Explainable AI is an emerging field focused on creating machine learning models that are more transparent and easier to interpret. This is crucial for increasing trust and adoption in industries like healthcare and finance.
Federated Learning
Federated learning allows models to be trained across multiple devices without sharing the raw data. This has huge potential for privacy sensitive applications.
Quantum Machine Learning
Quantum computing is still in its early stages, but it has the potential to revolutionize machine learning by enabling faster computations and solving problems that are currently intractable for classical computers.
What is machine learning?
Machine learning is a subset of artificial intelligence where algorithms learn patterns from data and make predictions or decisions without explicit programming.
What is supervised learning?
Supervised learning is a type of machine learning where the model is trained on labeled data to predict outcomes for new, unseen data.
What is unsupervised learning?
Unsupervised learning involves training models on data without labels to find hidden patterns or relationships in the data.
What is reinforcement learning?
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties.
What is a decision tree?
A decision tree is a machine learning algorithm that splits data into subsets based on feature values, resulting in a tree like structure used for classification or regression.
What is overfitting?
Overfitting occurs when a model learns the training data too well, including noise and outliers, resulting in poor performance on new, unseen data.
What is feature engineering?
Feature engineering is the process of selecting and transforming raw data into meaningful features that improve the performance of machine learning models.
What is the difference between regression and classification?
Regression predicts continuous values e.g. predicting house prices, while classification predicts discrete categories e.g. classifying emails as spam or not spam.
What is a neural network?
A neural network is a machine learning model inspired by the human brain, consisting of layers of interconnected neurons that process data for tasks like image recognition and natural language processing.
What is cross validation?
Cross-validation is a technique used to assess the performance of a machine learning model by splitting the data into multiple subsets and training the model on different combinations of these subsets.
Conclusion
Machine learning is transforming the world as we know it, with applications across virtually every industry. Although the concepts can initially seem daunting, understanding the basics is the first step toward mastering this powerful technology. As machine learning continues to evolve, it will open up new possibilities for innovation and change. Whether you are a beginner or looking to deepen your knowledge, the world of machine learning offers endless opportunities for exploration and growth. By continuing to learn and adapt, you can become a part of this exciting journey into the future.
